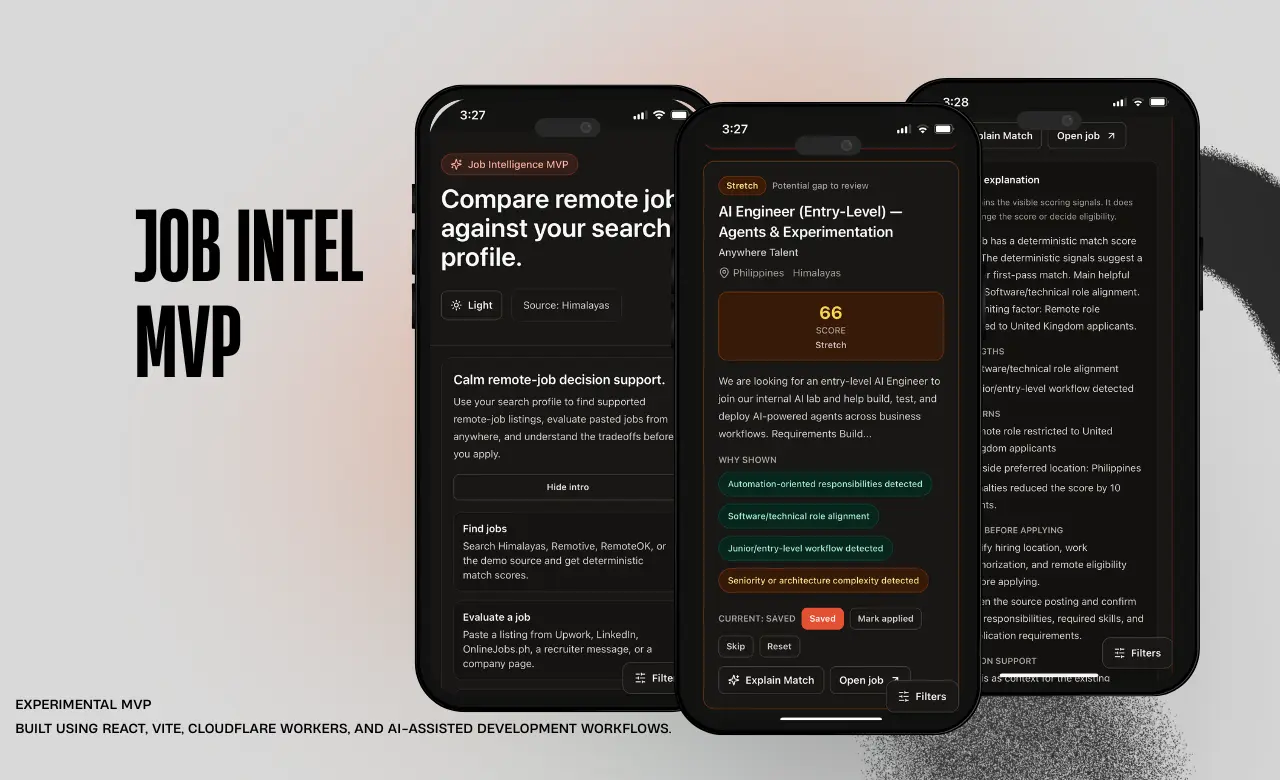
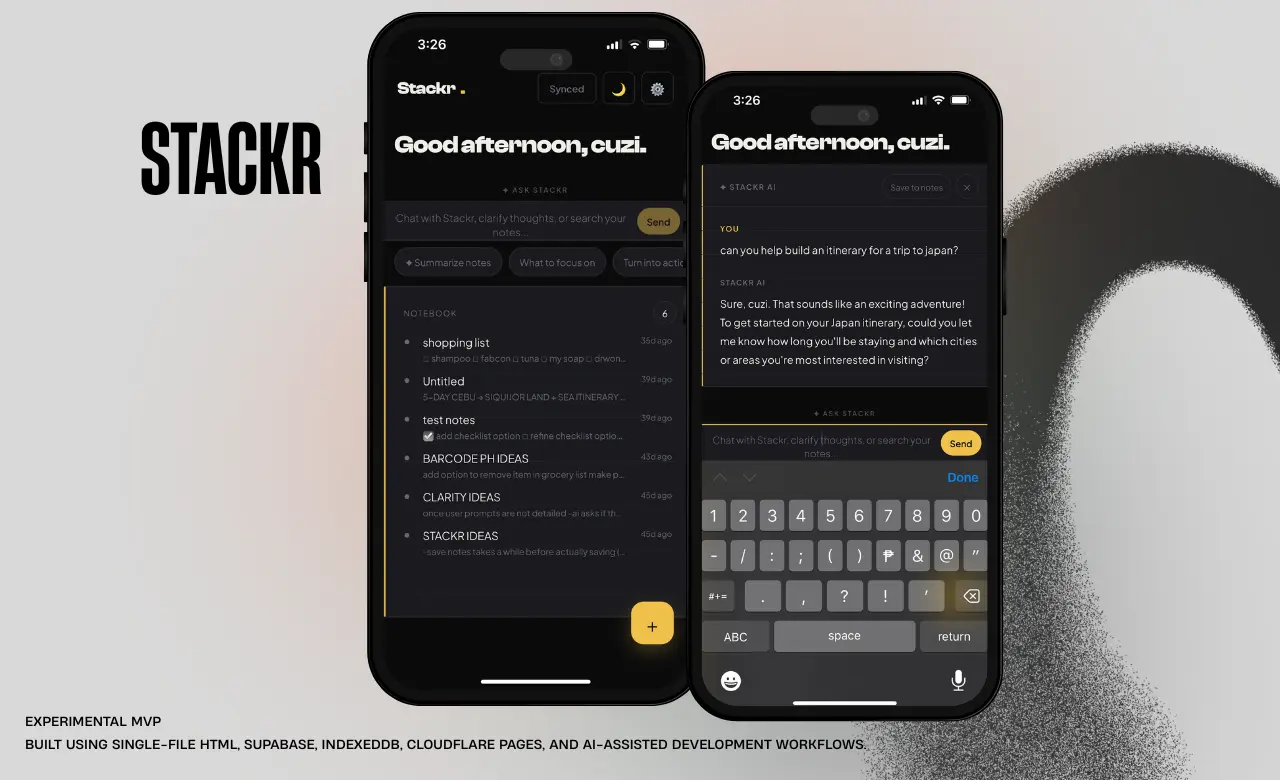
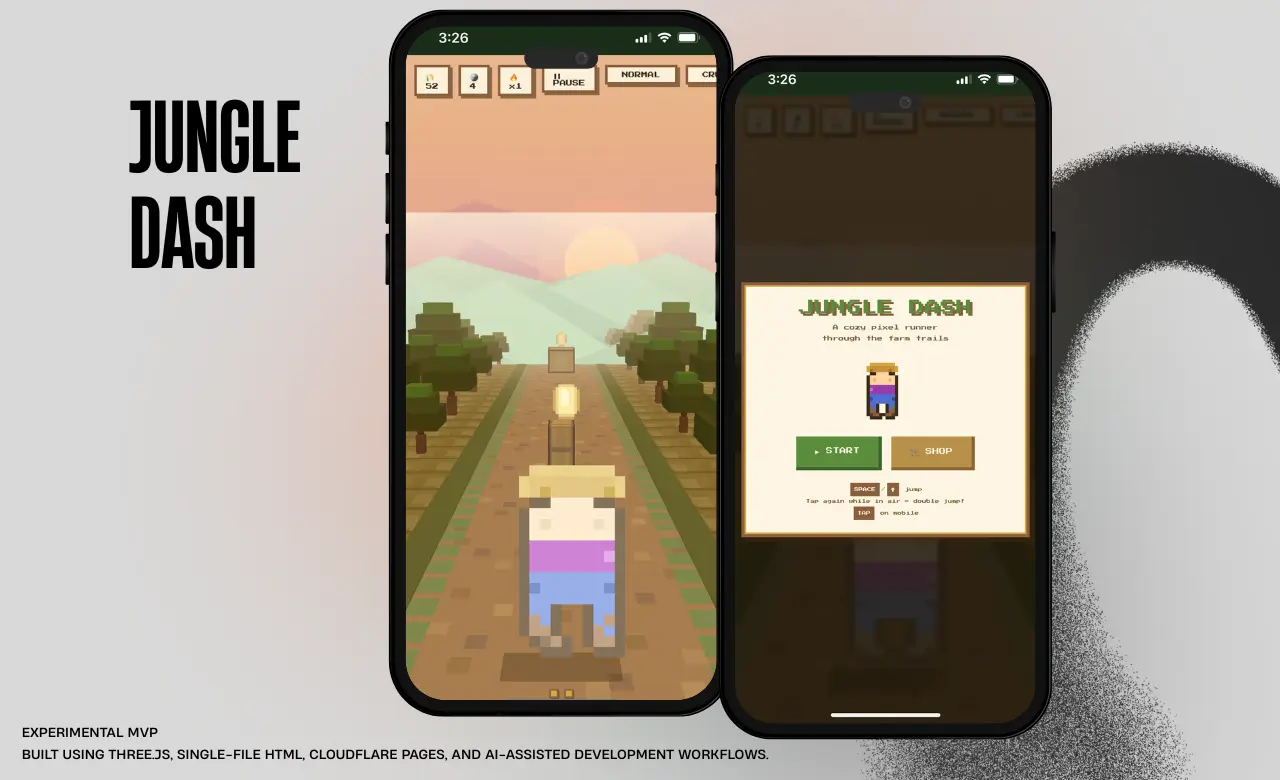
Available for work
I build and test AI systems
in the same loop.
Leo Mari Cuizon · AI-assisted QA · Workflow Testing · Lightweight PWA & Web Projects
Mobile apps · Web · LLM output evaluation · AI workflow systems · n8n automation · AI content workflows · Edge cases